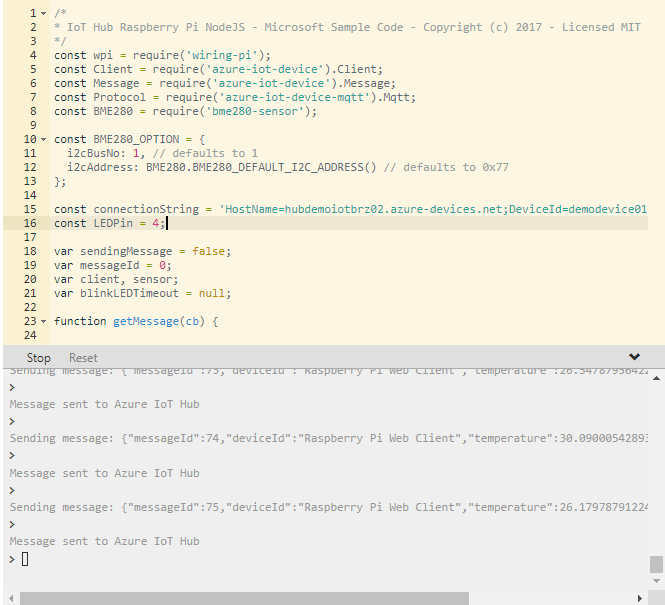
Olá Pessoal!
Feliz Ano Novo…
Para iniciarmos bem o ano, vou falar um pouco sobre um produto que tenho utilizado bastante ultimamente, o Azure Data Factory.
Data Factory é um serviço de integração (ETL/ELT) disponível no Azure, tendo como diferencial a sua facilidade na construção soluções de integrações híbridas. Esse serviço também se destaca pela quantidade de conectores com suporte nativo disponíveis, os quais já passam de 70. Vocês podem conferir os detalhes gerais na página abaixo abaixo:
https://azure.microsoft.com/pt-br/services/data-factory/
Apesar de uma série de benefícios existentes em sua utilização, inclusive em sua nova versão (V2), o Data Factory ainda trás limitações quando comparamos com alguns recursos existentes no SQL Server Integration Services, principalmente na parte das transformações disponíveis.
Fora algumas limitações, o Data Factory trás ganhos na orquestração visual, tendo uma quantidade de conectores grande, além de um throughput elevado e inclusive, permitindo que pacotes On-premises do SSIS sejam executados no serviço.
No exemplo abaixo, será demonstrado como fazer a configuração do Data Factory para pode executar pacotes do SSIS. O seguinte cenário será utilizado como base, existe um pacote do SSIS (On-premises) que faz a carga de dados de um arquivo estruturado em um diretório de rede para o SQL Server local, o objetivo é levar de maneira simples esse pacote para o Data Factory.
Uma vez que o serviço do Data Factory tenha sido criado e essa etapa é relativamente simples, você deve acessar a visão geral do recurso e ir até a página de “Autor e Monitor”.
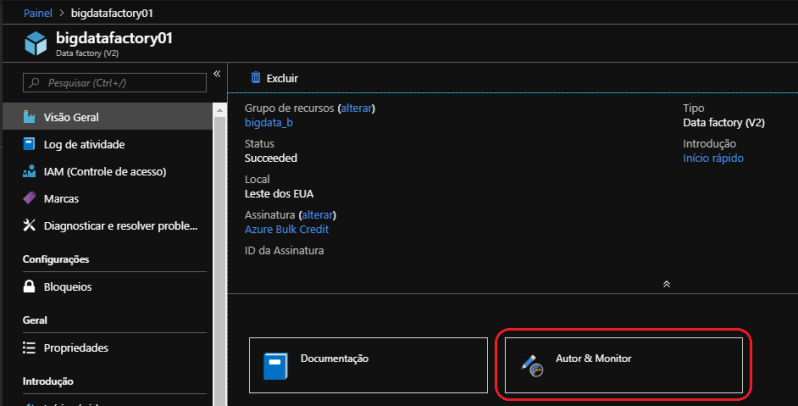

Nessa tela inicial está disponível acesso as principais funções do Data Factory, além de tutoriais e materiais de apoio para realizar as principais operações no serviço.
A primeira opção é referente a criação de “Pipeline”, que são agrupamentos lógicos de atividades que juntos realizam a tarefa. A segunda opção de “Copy Data” inicia uma atividade de cópia entre dois armazenamento de dados, podendo estar On-premises ou Cloud. A terceira opção de “Configure SSIS Integration Runtime” apoia exatamente na atividade que iremos realizar. Por último temos o “Set up Code Repository” para realizar a associação do repositório de versionamento com o Data Factory.
Avance para seleção da opção “Configure SSIS Integration Runtime”. O “Integration Runtime” é uma estrutura computacional do Data Factory que fornece algumas capacidades de integração de dados entre ambientes de redes diferentes. No Data Factory uma atividade define a ação a ser realizada, um “Linked Service” define o armazenamento de dados de destino e o “Integration Runtime” fornece a ponte entre a atividade e o “Linked Service”. A diferença do “Azure-SSIS Integration Runtime” para as outras opções, se resume a capacidade de executar pacotes nativos do SSIS no Data Factory com recursos do Azure VM em Cluster dedicados para essa tarefa.

Veja que existe a seleção do hardware a ser utilizado, assim como, a quantidade de nodes. Quando comparado a precificação do “SSIS Integration Runtime” com a pipeline sem integração, o custo é muito maior, sendo assim, o custo deve ser um fator importante na decisão na utilização desse tipo de solução integrada.
A próxima etapa no setup é referente a configuração do Azure SQL Database que irá hospedar a base do “SSIS Catalog”. O server já existia na subscrição, sendo assim, só foi necessário preencher as informações de acesso e selecionar o “Tier”.

Se necessário altere as configurações avançadas disponíveis e em caso de dúvida, repare que existe um ícone de exclamação próximo ao item, ao passar o mouse por cima será possível obter mais informações sobre a função de determinada configuração, em nosso caso vou deixar o padrão e finalizar.

O deploy irá demorar alguns minutos e ao concluir será exibido dentro do Data Factory, além da base do SSISDB criada automaticamente no SQL Database.


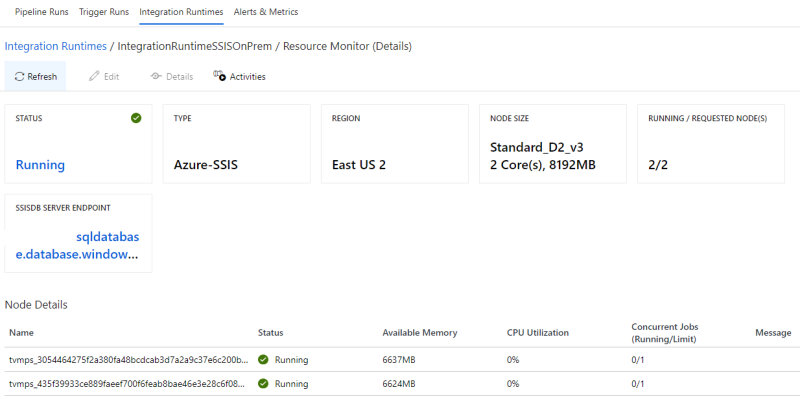
Ao selecionar a opção “View Runtime Integration Detail” é possível acessar uma página com maior detalhes de configuração, mostrando também informações de consumo dos nodes.
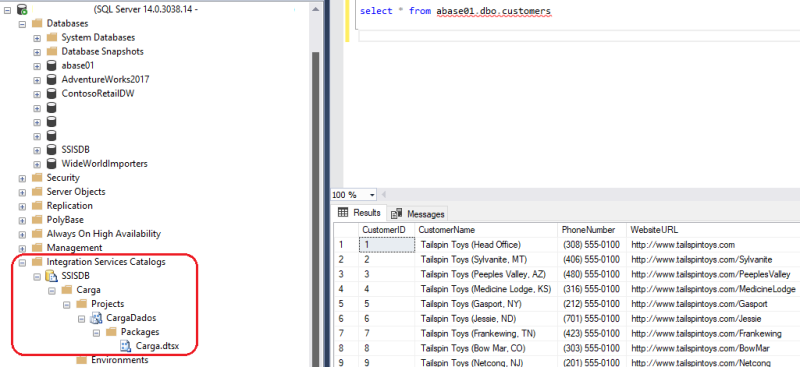
Agora que terminamos essa parte do setup no Data Factory, vamos ao ambiente On-premises. Temos o projeto “CargaDados” já existente no Visual Studio (SSDT) com o pacote “Carga”. No pacote “Carga” temos uma tarefa para extração dos dados de determinado arquivo estruturado e inserção deste em um banco SQL Server On-premises.

Esse projeto teve seu deploy feito para o Integration Services Catalogs da mesma instância do SQL Server On-premises.
Precisamos agora partir para segunda etapa, na qual faremos o deploy do projeto para o Azure SQL Database que está hospedando a estrutura do Integration Services Catalogs (SSISDB). A etapa é igual a qualquer outro procedimento de deploy, na tela de publicação do Integration Services dentro do Visual Studio (SSDT), deve ser selecionado o servidor e avançar para o deploy.

Uma vez concluído a estrutura do Integration Services Catalogs no Azure SQL Database será criada.

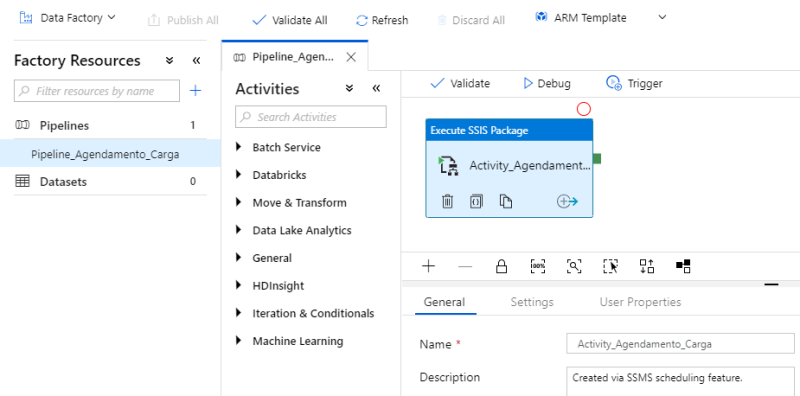
Por último, faremos o agendamento para execução periódica do pacote, essa etapa pode ser feita também por dentro do SSMS ao clicar com o botão direito no pacote e ir até a opção “Schedule”.

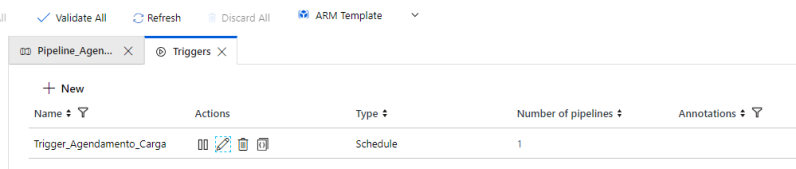
O recurso de agendamento pelo SSMS criará a “Pipeline”, Atividade e “Trigger” dentro do Data Factory, seguindo os parâmetros passados na configuração.
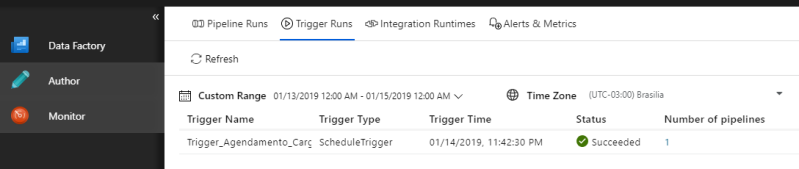
A execução da “Trigger” pode ser monitorada na guia “Monitor” na opção “Trigger Runs”.
Concluímos todos os passos da solução! Vale ressaltar que, não são todos os caso que a utilização do Data Factory com o SSIS é vantajoso, existem restrição não abordadas aqui e que devem ser vistas na documentação, apesar disso, é um recurso que funciona muito bem, além de ter uma fácil configuração. Devemos também lembrar que, o Data Factory fornece outros 2 tipos de “Integration Runtime”, não discutidos nesse artigo, um para uso com atividades no Azure e outro redes privadas.

Seguem alguns links complementares que irão ajudar na utilização do Azure Data Factory, inclusive relacionado a funcionalidade de integração com o SSIS.
https://docs.microsoft.com/pt-br/azure/data-factory/concepts-integration-runtime
https://www.blue-granite.com/blog/the-right-tool-for-the-job-azure-data-factory-v2-vs.-integration-services
https://azure.microsoft.com/pt-br/pricing/details/data-factory/
https://docs.microsoft.com/en-us/azure/data-factory/create-azure-ssis-integration-runtime
https://docs.microsoft.com/pt-br/sql/integration-services/lift-shift/ssis-azure-connect-to-catalog-database?view=sql-server-2017
Até a próxima!